Generative models represent a cornerstone of modern artificial intelligence, aiming to learn the underlying probability distribution of a given dataset and subsequently synthesize novel samples indistinguishable from genuine data. Recent years have witnessed transformative advancements in this domain, with models achieving remarkable fidelity in generating complex, high-dimensional data across diverse modalities such as images, text, audio, and even scientific structures. This progress has unlocked a plethora of applications, from creative content generation to drug discovery and robotics.
Among the leading contemporary approaches, Latent Diffusion Models (LDMs) and Conditional Flow Matching (CFM) have emerged as particularly influential paradigms. LDMs, an evolution of diffusion probabilistic models, have established themselves as a dominant force, particularly in visual synthesis, renowned for their ability to generate exceptionally high-quality and diverse images. These models operate by systematically introducing noise to data and then learning to reverse this process, typically within a compressed latent space for computational efficiency. Concurrently, Conditional Flow Matching has garnered significant attention as a newer, highly promising framework. CFM offers an alternative path to generative modeling, often characterized by more efficient training procedures and faster inference. It typically involves learning a direct, continuous transformation, often conceptualized as a “flow,” that maps a simple prior distribution (e.g., Gaussian noise) to the complex data distribution. Both LDMs and CFM share the fundamental goal of transforming unstructured noise into structured, meaningful data, yet they achieve this via distinct mathematical formalisms and operational mechanisms.
The rapid progression from pixel-space diffusion models to LDMs, alongside the concurrent development and rise of CFM, highlights a significant trend within the generative AI research community. This trend is not merely a pursuit of higher sample quality but also reflects a concerted effort towards developing models that are computationally more tractable, flexible, and efficient. The initial iterations of diffusion models, while powerful, often operated directly in the high-dimensional pixel space, leading to substantial computational demands. LDMs were a direct response to this challenge, leveraging a compressed latent space to drastically reduce computational overhead without a prohibitive sacrifice in generation quality. Almost in parallel, CFM and other flow-based methodologies have been developed with a keen emphasis on training efficiency, often through “simulation-free” objectives, and rapid sample generation, facilitated by fewer sampling steps or direct integration of ordinary differential equations (ODEs). This convergence of goals—achieving powerful generative capabilities that are also practical to train and deploy—is a driving force in the field. The “latent” aspect of LDMs and the “direct path” characteristic of CFM both underscore this overarching objective of optimizing resource utilization while pushing the boundaries of generative performance.
Furthermore, the concept of “conditioning” has become central to the practical utility and widespread adoption of both LDM and CFM. Generative models have evolved significantly from producing unconditional, random samples to enabling highly controllable and task-specific synthesis. The sophistication and flexibility of conditioning mechanisms represent a key frontier for innovation and a critical differentiator between model capabilities. LDMs, for instance, gained widespread acclaim through their powerful text-to-image conditioning capabilities, as exemplified by systems like Stable Diffusion. Similarly, CFM, as its name explicitly suggests, is fundamentally built around the idea of conditioning. Research in both areas demonstrates a continuous push towards incorporating increasingly complex and diverse conditional inputs, from scene graphs and semantic maps in LDMs to multimodal inputs like images and story texts in CFM-based systems such as MusFlow. This strong emphasis on precise control over the generation process, guided by a rich variety of input signals, is paramount for unlocking the full potential of these models in real-world applications and remains a vibrant area of ongoing research.
This report aims to provide an in-depth, expert-level comparative analysis of Latent Diffusion Models and Conditional Flow Matching. It will delve into their respective theoretical foundations, architectural designs, conditioning mechanisms, performance characteristics, key applications, and emerging trends, including hybrid approaches. Understanding the nuances, strengths, and limitations of these sophisticated generative paradigms is crucial for researchers and practitioners seeking to leverage or advance the state of the art in generative AI.
Latent Diffusion Models (LDMs): Mastering Generation through Iterative Denoising
Latent Diffusion Models (LDMs) have risen to prominence as a powerful class of generative models, particularly for high-resolution image synthesis. They build upon the principles of diffusion models but introduce a critical efficiency improvement by operating in a compressed latent space.
Core Generative Process
The generative capability of LDMs is rooted in a two-stage process: a forward noising stage that progressively corrupts data, and a learned reverse denoising stage that reconstructs data from noise.
Forward Noising (Diffusion Process):
The forward process systematically introduces Gaussian noise to an input data sample 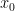
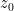



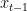
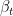



Reverse Denoising (Learned Generation Process):
The core learning task in LDMs is to reverse this noising process. This involves training a model, typically a neural network, to predict the conditional distribution 



The Critical Role of the Latent Space:
A defining characteristic of LDMs is that the diffusion and denoising processes are performed not in the high-dimensional pixel space of images, but in a lower-dimensional latent space. This architectural choice significantly reduces the computational burden and memory footprint associated with training and inference, making it feasible to work with high-resolution images. This latent space is typically learned by a separate autoencoder, most commonly a Variational Autoencoder (VAE). The VAE’s encoder compresses an image into a latent vector 

The decision to operate within a latent space represents a fundamental design trade-off. While it grants substantial computational advantages and allows the diffusion process to focus on modeling the more semantically meaningful variations in the data, it also introduces a dependency on the quality of the VAE. The compression performed by the VAE is inherently lossy, and if the VAE cannot faithfully encode and decode fine-grained details or complex textures, these limitations will manifest as artifacts or a loss of fidelity in the final generated samples. Research efforts, such as those detailed in [11], actively explore methods to enhance VAEs tailored for LDMs. This work highlights an “optimization dilemma”: visual tokenizers with higher feature dimensions can improve reconstruction quality but subsequently demand larger diffusion models and more extensive training to achieve comparable generative performance. This underscores that the VAE is not merely a peripheral pre-processing component but an integral element whose characteristics profoundly influence the overall LDM system’s performance and its inherent limitations. The “latent” nature of LDMs is thus both a key strength and an ongoing source of research challenges.
Key Architectural Components (e.g., Stable Diffusion)
The architecture of a typical LDM, exemplified by models like Stable Diffusion, comprises several key components that work in concert.
Variational Autoencoder (VAE):
As mentioned, the VAE is responsible for creating the compressed latent space.
The encoder maps a high-resolution input image from pixel space to a compact latent representation
The decoder takes a (denoised) latent representation
The fidelity of this VAE is paramount; deficiencies in its ability to compress and decompress information can lead to undesirable artifacts or a loss of crucial image details in the generated outputs.
U-Net for Denoising:
The U-Net is the workhorse of the LDM, operating entirely within the latent space. Its primary function is to predict the noise (or, equivalently, the clean latent 
The U-Net in LDMs, while architecturally similar to those used in other image processing tasks, plays a highly specialized role. It is not merely a generic denoising network but rather a sophisticated function approximator that learns the complex, conditional pathways from noise to structured latent representations. Its capacity to effectively integrate multiple streams of information—the noisy latent input
Text Encoders and Conditioning Inputs:
To enable conditional generation, such as text-to-image synthesis, LDMs employ encoders to transform conditioning inputs into a format usable by the U-Net. For text prompts, fixed, pretrained text encoders like CLIP (Contrastive Language-Image Pre-training) are commonly used to convert the text into rich embedding vectors. These embeddings are then typically injected into the U-Net via cross-attention layers, allowing the textual information to guide the denoising process at each step.
The evolution observed in prominent LDM families, such as Stable Diffusion (e.g., from the original version to SDXL and SD 3.0), reveals a clear trend towards incorporating larger and more complex components to push performance boundaries. For instance, SDXL features a significantly larger U-Net backbone and utilizes two text encoders instead of one, enhancing its expressive power and the quality of generated images. More radically, SD 3.0 moves away from a U-Net architecture to a Rectified Flow Transformer backbone, indicating a willingness to adopt entirely new architectural paradigms for the core denoising network. This progression suggests that while the shift to a latent space provides foundational efficiency gains, further substantial improvements in generation quality, conditioning fidelity, and overall capability often necessitate scaling up model size and architectural sophistication. This mirrors broader trends in deep learning, where increased scale frequently correlates with enhanced performance. Consequently, while LDMs are more efficient than their pixel-space predecessors, state-of-the-art versions still demand considerable computational resources for training and, to a lesser extent, for inference.
Conditioning Mechanisms in LDMs
LDMs offer versatile conditioning capabilities, allowing for guided and controlled generation.
Text-to-Image Synthesis: This is the most prominent application, where textual prompts, processed by encoders like CLIP, guide image generation.
Image-to-Image Translation: LDMs can be conditioned on input images for tasks like style transfer, image editing, inpainting (filling missing parts), and outpainting (extending an image).
Spatial and Structural Conditioning: Advanced techniques like ControlNet and T2I-Adapters enable fine-grained control over the generated image’s structure by conditioning on spatial inputs such as depth maps, Canny edges, human poses, or segmentation maps. These often involve fine-tuning a copy of the LDM’s U-Net or training lightweight adapter modules that inject the control signal.
Domain-Specific Conditioning: LDMs can be adapted for specialized domains. For example, PathLDM utilizes pathology reports, summarized by a large language model like GPT, as textual conditioning for generating histopathology images, demonstrating the potential for nuanced, domain-specific guidance.
Scene Graph Conditioning: Research has explored using scene graphs, which provide a structured representation of objects and their relationships, as a more unambiguous conditioning signal than free-form text, aiming for more precise control over image content and layout.
Strengths:
State-of-the-Art Sample Quality and Diversity: LDMs are renowned for producing highly realistic and diverse samples, particularly in image generation, often setting the benchmark for quality.
Strong Conditioning Capabilities: They can be effectively conditioned on various modalities, most notably text, enabling intuitive control over the generation process.
Computational Efficiency (Relative to Pixel-Space Diffusion): Operating in the latent space significantly reduces computational demands compared to earlier diffusion models that worked directly on pixels.
Limitations:
Iterative Sampling Speed: The iterative nature of the denoising process, requiring multiple steps (typically dozens to hundreds), can make sampling relatively slow, although this is much faster than pixel-space diffusion. Techniques like Latent Consistency Models (LCMs) aim to distill LDMs into versions requiring fewer steps, but this can sometimes involve a trade-off in sample quality.
VAE-Induced Artifacts and Information Loss: The VAE compression can lead to loss of fine details or the introduction of reconstruction artifacts, impacting the final image quality. The quality of the VAE is a critical bottleneck.
Training Costs: Training state-of-the-art LDMs from scratch is computationally intensive and typically requires very large datasets.
Susceptibility to Adversarial Attacks: LDMs have been shown to be vulnerable to adversarial attacks, where small, imperceptible perturbations to inputs can lead to incorrect or low-quality outputs.
Aliasing and Inconsistency: Standard LDMs can exhibit sensitivity to small shifts or perturbations in the input noise or conditioning, potentially leading to inconsistent outputs. Research efforts like Alias-Free Latent Diffusion Models (AF-LDM) are being developed to improve shift-equivariance and generation consistency.
VAE Optimization Dilemma: As noted earlier, improving VAE reconstruction quality by increasing the dimensionality of latent tokens can necessitate substantially larger diffusion models and more training iterations to achieve comparable generation performance, creating a challenging trade-off.
Conditional Flow Matching (CFM): Direct Trajectory Learning for Efficient Generation
Conditional Flow Matching (CFM) has emerged as a compelling alternative and, in some cases, a complementary approach to diffusion models. It offers a distinct paradigm for generative modeling, focusing on learning direct, continuous transformations between distributions, often leading to significant gains in training and inference efficiency.
Core Generative Process
The essence of CFM lies in learning a time-dependent vector field that deterministically transports samples from a simple prior distribution to a complex target data distribution.
Learning Vector Fields to Map Distributions:
CFM aims to learn a velocity field, denoted as 



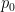
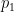

Ordinary Differential Equations (ODEs) as the Generative Pathway:
The learned vector field 
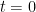
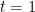

Conditional Flow Matching (CFM) Objective:
A key innovation in CFM is its training objective. Instead of attempting to directly learn the often intractable marginal vector field 







The Role of Optimal Transport (OT) Principles:
Optimal Transport theory plays an increasingly important role in enhancing CFM. OT provides a principled way to define “straighter” or more efficient probability paths between the source distribution
Architectural Considerations for Modeling Velocity Fields
The vector field 


For image generation tasks, U-Net architectures, similar to those used in diffusion models, have been mentioned as suitable choices for parameterizing 
Advanced Conditioning in CFM
CFM offers a highly flexible framework for incorporating conditioning information, enabling precise control over the generation process.
Conditional Velocity Fields: The very foundation of the CFM training objective is built around learning conditional velocity fields
Conditional Variable Flow Matching (CVFM): A significant extension, CVFM, addresses scenarios involving continuous conditioning variables and, critically, datasets where the samples and their corresponding conditioning variables are unpaired. This is a common challenge in many scientific and engineering domains where collecting perfectly paired data is expensive or infeasible. CVFM achieves this by employing two simultaneous sample-conditioned flows (one for the main variable and one for the conditioning variable), a conditional Wasserstein distance, and a condition-dependent loss reweighting kernel to facilitate conditional optimal transport, even with unpaired observations. This capability to handle unpaired data, particularly with continuous conditioning variables, positions CFM (via CVFM) strongly for real-world applications in fields like materials science or manufacturing process modeling, where LDMs (which typically rely on large, paired datasets) might be harder to apply effectively. This adaptability to challenging data scenarios could be a major differentiating factor for CFM.
Multimodal Conditioning: CFM models can be designed to accept and integrate information from multiple modalities. For example, MusFlow, a CFM-based model for music generation, can take diverse inputs such as images, story texts, and music captions. It achieves this by first encoding these varied inputs into their respective embedding spaces and then using adapter networks (e.g., MLPs) to align these embeddings into a common semantic space (e.g., an audio CLAP embedding space). This fused multimodal embedding then guides the CFM process to generate music that is contextually relevant to the combined inputs.
Strengths:
Faster Training: The simulation-free objective, which recasts training as a direct regression problem, generally leads to faster training compared to diffusion models or traditional CNF likelihood training.
Faster Inference/Sampling: CFM models, especially those guided by OT paths, often require significantly fewer function evaluations (NFE) during ODE solving to produce high-quality samples. This results in faster inference speeds.
Flexible Framework: CFM is adaptable to a wide range of data types (images, audio, tabular data, trajectories) and can incorporate sophisticated conditioning mechanisms.
Competitive Performance: CFM has demonstrated performance on par with or exceeding state-of-the-art diffusion models in terms of standard metrics like Frechet Inception Distance (FID) and negative log-likelihood (NLL) on benchmark datasets.
Handling Unpaired Conditioning: Through extensions like CVFM, CFM can effectively learn from datasets where samples and conditioning variables are not paired, a significant advantage in many real-world scenarios.
Potential Challenges:
Sample Diversity: While sample quality is high, initial comparisons suggested that CFM might produce less diverse samples than diffusion models. However, this is an active area of research, and techniques to enhance diversity are being explored. The deterministic nature of the ODE sampling (given a specific
Sensitivity to Probability Path Choice: The performance of CFM, particularly in specialized tasks like spatio-temporal forecasting, can be sensitive to the specific choice of the probability path model used to define the conditional vector fields.
Complexity of Vector Fields: For highly complex and multi-modal data distributions, learning the “correct” global vector field, even via the simpler conditional regression targets, remains a challenging task. The efficacy of CFM hinges on the ability of the chosen conditional paths and vector fields to adequately guide the learning process.
Numerical ODE Solver Errors: While standard ODE solvers are used for sampling, numerical errors can accumulate, especially if a very small number of integration steps are used in pursuit of maximum speed. This can potentially affect the quality of the generated samples.
Comparative Analysis: LDM vs. CFM
Latent Diffusion Models (LDMs) and Conditional Flow Matching (CFM) represent two leading paradigms in generative modeling. While both aim to transform noise into data, their underlying principles, architectures, and performance characteristics exhibit notable differences.
Fundamental Mathematical Principles
The mathematical foundations of LDMs and CFM diverge significantly, impacting their generative mechanisms.
LDMs: The forward noising process in LDMs is typically modeled by a Stochastic Differential Equation (SDE), or its discrete-time analogue, which describes the gradual addition of random noise. The reverse generation process then aims to learn to reverse this SDE (or a corresponding ODE, often called the probability flow ODE). SDEs inherently incorporate a random component, making them suitable for modeling systems where evolution involves intrinsic randomness or complex, unmodeled factors. Even when using deterministic ODE samplers for LDMs, the underlying model is trained to reverse a stochastic process.
CFM: In contrast, CFM typically learns a deterministic mapping defined by an Ordinary Differential Equation (ODE): 
This fundamental mathematical distinction—SDE-based iterative refinement versus ODE-based direct trajectory learning—has profound implications. The inherent stochasticity in the LDM framework (even if only in the conceptual forward process that the reverse process is trained to invert) can naturally lead to more varied outputs for the same high-level conditioning, as the model navigates a path with many potential small deviations. This might be a contributing factor to the strong diversity often observed in LDM outputs. Conversely, the deterministic nature of the ODEs learned by CFM results in a single, fixed trajectory from a given noise vector
Training Dynamics and Inference Efficiency
The differences in mathematical underpinnings translate to distinct training and inference characteristics.
Training Speed: LDMs can involve lengthy training procedures due to their iterative nature, the need to train across many noise levels, and often large model sizes, although operating in the latent space provides significant speedups over pixel-space diffusion. CFM generally offers faster training. Its simulation-free objective, which involves a direct regression of the model’s vector field against a target conditional vector field, is computationally less intensive per step. CFM variants incorporating Optimal Transport (OT-CFM) and those operating in latent spaces (Latent-CFM) have demonstrated notable training efficiency gains.
Inference Speed (Sampling): LDMs traditionally require a large number of denoising steps (e.g., 50 to 1000) for high-quality sample generation, making inference relatively slow. While distillation techniques (e.g., Latent Consistency Models) can significantly reduce the number of required steps, this may sometimes come at the cost of sample quality. CFM, on the other hand, typically exhibits faster inference. The often more direct or “straighter” paths learned by CFM, particularly when guided by OT principles, allow for high-quality sample generation with a much smaller number of function evaluations (NFEs) during ODE solving (e.g., 1 to 20 steps).
Computational Cost: Training state-of-the-art LDMs demands substantial computational resources (GPUs, time, large datasets). Inference cost is proportional to the number of sampling steps. CFM generally presents a lower computational barrier for training due to its efficient objective. Its inference cost is also typically lower owing to the reduced NFE requirement.
Convergence: Empirical evidence suggests that CFM, particularly when combined with OT paths, can achieve faster convergence during training compared to traditional diffusion model training regimes.
Sample Quality and Diversity
Both LDMs and CFM are capable of producing high-quality samples, but they may differ in terms of diversity.
LDMs: Excel in generating highly diverse and photorealistic images, often setting the state of the art in visual synthesis. Their iterative refinement process and stochastic nature appear conducive to exploring a wide range of variations within the data distribution.
CFM: Achieves sample quality (as measured by metrics like FID and NLL) that is competitive with, and in some cases surpasses, LDMs and other diffusion-based methods, especially when OT-CFM is employed. Initial assessments suggested that CFM might yield less sample diversity compared to DMs. This is an active area of research, with ongoing efforts to enhance the diversity of CFM-generated samples.
Flexibility and Control via Conditioning
Conditioning is a critical aspect for the practical application of generative models.
LDMs: Offer strong conditioning capabilities, most notably for text-to-image generation using CLIP embeddings. Advanced methods like ControlNet provide fine-grained spatial control by conditioning on inputs like depth maps, canny edges, or human poses. LDMs typically rely on large, paired datasets for training these conditional behaviors.
CFM: Provides a highly flexible conditioning framework. As discussed, Conditional Variable Flow Matching (CVFM) extends CFM to handle continuous conditioning variables and, crucially, unpaired datasets where sample data and their corresponding conditioning variables need not be in direct correspondence. Multimodal conditioning, as seen in MusFlow (generating music from images, text, and captions), is also effectively implemented with CFM. Furthermore, some CFM approaches can enable zero-shot conditional generation without requiring model retraining for new conditioning signals, by iteratively refining samples to satisfy constraints.
Robustness, Scalability, and Known Issues
LDMs:
Robustness: Have shown susceptibility to adversarial attacks and can suffer from aliasing or inconsistencies due to small input shifts, although research like AF-LDM aims to mitigate this.
Scalability: LDMs scale effectively with increased data and model size, generally leading to improved performance, as seen in the evolution of models like Stable Diffusion (SDXL, SD3).
Known Issues: The VAE can be a bottleneck, potentially causing information loss or artifacts. Slow sampling speed (without distillation) remains a concern for some applications.
CFM:
Robustness: The training process for CFM, particularly with well-chosen paths, can be more stable than some diffusion model training regimes.
Scalability: CFM has demonstrated good scalability to high-dimensional data, including images.
Known Issues: Performance can be sensitive to the choice of the probability path model. Ensuring sufficient sample diversity for highly multi-modal distributions is an ongoing area of focus.
The choice between LDM and CFM is increasingly nuanced, becoming less about universal superiority and more about selecting the model whose trade-off profile best aligns with the specific requirements of a given application. For tasks where maximizing sample diversity and leveraging vast, pretrained vision models are paramount (e.g., general artistic image generation from text), LDMs might be the preferred choice. Their established ecosystem and proven ability to generate a wide array of high-fidelity visual content are significant advantages. Conversely, CFM may excel in scenarios where inference speed is critical, where direct control over generation trajectories is beneficial (e.g., robotics), or for applications involving unique conditioning requirements, such as scientific modeling with sparse or unpaired data. For instance, a materials scientist needing to rapidly generate physically plausible material microstructures based on limited, unpaired experimental process parameters would likely find CFM, particularly variants like CVFM, more suitable. This context-dependent suitability underscores the distinct ecological niches these powerful generative paradigms are beginning to occupy.
Moreover, “Flow Matching” as a general training paradigm appears to be broader than just CFM. It has been shown that the FM objective can be used to train diffusion models themselves, potentially leading to more robust and stable training outcomes. This suggests that FM is a foundational technique for training models that learn transformations over time or steps, with CFM being a specific, highly effective instantiation of this principle that often uses non-diffusion paths (like OT paths) for enhanced efficiency. This elevates FM from merely “an alternative to diffusion” to a more encompassing training methodology that can benefit a variety of generative models reliant on learning sequential transformations.
Comparative Performance Metrics Summary
| Feature | Latent Diffusion Models (LDMs) | Conditional Flow Matching (CFM) | Supporting Evidence |
| Underlying Math | SDEs (primarily), iterative denoising | ODEs, direct vector field regression, Optimal Transport | 1 |
| Training Speed | Slower, iterative | Faster, simulation-free regression | 3 |
| Inference Speed | Slower (many steps, e.g., 20-1000), can be distilled | Faster (fewer steps, e.g., 1-20), straighter paths (esp. OT-CFM) | 3 |
| Sample Diversity | Generally higher, excels in diversity | Initially considered lower, active research area for improvement | 3 |
| Sample Quality (FID) | State-of-the-art | Competitive, OT-CFM achieves SOTA on benchmarks | 9 |
| Likelihood (NLL/BPD) | Good | Competitive, OT-CFM achieves SOTA on benchmarks | 9 |
| Conditioning | Strong (text, image, ControlNet), typically paired data | Highly flexible, unpaired data (CVFM), multimodal, zero-shot cond. | 4 |
| Latent Space Usage | Yes (VAE for compression) | Can be used in latent space (Latent-CFM) or pixel/feature space | 5 |
| Key Advantage | High sample diversity, established SOTA in many vision tasks | Training/inference speed, flexibility, strong theoretical grounding (OT) | 3 |
| Key Limitation | Inference speed, VAE artifacts | Ensuring diversity for complex distributions, path choice sensitivity | 3 |
Synergies and Hybrid Frontiers: Integrating LDM and CFM
The distinct strengths and weaknesses of Latent Diffusion Models (LDMs) and Conditional Flow Matching (CFM) have naturally led to research exploring hybrid approaches. These efforts aim to combine the best attributes of both paradigms, creating generative systems that are simultaneously diverse, high-quality, efficient, and controllable.
The primary motivation for developing hybrid LDM-CFM models is to achieve a synergistic effect:
Combining Strengths: The goal is to harness the renowned sample diversity and high fidelity of LDMs with the superior training and inference efficiency often associated with CFM, particularly its ability to learn direct and “straight” generation trajectories.
Addressing Limitations: Hybridization can also mitigate the inherent limitations of each individual approach. For example, CFM techniques might be employed to accelerate the inference process of an LDM or to refine the mappings within an LDM’s latent space more efficiently.
The development of such hybrid models signifies a maturation in the field of generative modeling. It reflects a shift from viewing different model families as mutually exclusive competitors towards a more nuanced understanding where specific components and principles from each can be strategically integrated. Researchers are increasingly identifying the unique advantages offered by different generative mechanisms (e.g., iterative refinement for diversity, direct path learning for speed) and are seeking to combine these in a modular fashion to create more powerful and versatile systems.
Examples of Combined Approaches
Several innovative hybrid architectures and training strategies have been proposed:
Flow Matching Boosting Latent Diffusion: This approach typically involves introducing a Flow Matching module into the LDM pipeline, often positioned between a standard (potentially frozen) LDM used for generating an initial low-resolution, diverse latent representation, and the VAE’s decoder. The LDM component is leveraged for its strength in producing diverse content, while the FM module efficiently maps this low-resolution latent to a higher-dimensional latent space suitable for the decoder. This FM-based mapping can enhance resolution and detail more efficiently (i.e., with fewer steps or a simpler model) than extending the LDM’s iterative denoising process to higher resolutions. This strategy effectively decouples the generation of diversity (handled by the LDM) from the task of high-resolution refinement or upscaling in the latent space (handled by FM).
Latent-CFM: This class of models applies CFM principles directly within a latent space, often one that is pretrained using established deep latent variable models like VAEs. The rationale is to combine the computational benefits of operating in a compressed latent space (an idea central to LDMs) with the efficient training and inference dynamics of CFM. Latent-CFM aims to improve overall generation quality and training efficiency (e.g., achieving comparable results with up to 50% fewer training steps than standard CFM operating in pixel space) by effectively incorporating the structure of the data manifold, as captured by the latent space, into the CFM training process. These models can also facilitate conditional generation based on features extracted from the latent space, potentially offering more interpretable control. This demonstrates that CFM, like diffusion, can benefit significantly from operating on well-structured, lower-dimensional representations of data.
Diff2Flow: This represents a principled strategy for initializing and fine-tuning Flow Matching models using parameters from already pretrained diffusion models. By carefully aligning the interpolants, timesteps, and deriving FM-compatible velocity fields directly from the predictions of a diffusion model, Diff2Flow enables highly efficient parameter transfer. This allows for rapid development of capable FM models by leveraging the extensive knowledge captured in existing large-scale diffusion models, often through parameter-efficient fine-tuning techniques like LoRA (Low-Rank Adaptation). This facilitates a seamless transition or adaptation of generative capabilities between the diffusion and flow matching paradigms.
HybridVLA (Vision-Language-Action models for robotics): This architecture exemplifies a deeper integration of generative components within larger AI systems. HybridVLA incorporates both diffusion-based action generation (specifically using flow matching for the action prediction head) and autoregressive policy prediction within a single Large Language Model (LLM). The goal is to combine the sophisticated reasoning and instruction-following capabilities of VLMs with the precision and continuous control afforded by diffusion/FM-based action generation. Rather than simply concatenating separate models, HybridVLA aims to inject the diffusion modeling paradigm directly into the LLM’s generative process for actions.
Potential for Future Innovations
The exploration of hybrid LDM-CFM models is still in its early stages, with significant potential for future advancements:
Sophisticated Blending Strategies: Development of more advanced techniques for dynamically blending stochastic (diffusion-like) generation steps, which may enhance exploration and diversity, with deterministic (flow-like) steps, which can offer speed and precision.
Adaptive Pathways: Models that can dynamically choose between LDM-style iterative refinement and CFM-style direct path generation based on the specific task, intermediate generation quality, or computational budget.
CFM for Diffusion Model Refinement: Using CFM techniques not just for boosting resolution but also to “correct,” “straighten,” or accelerate the inference trajectories of existing pretrained diffusion models.
Unified Theoretical Frameworks: Further development of theoretical frameworks that can unify the principles of diffusion and flow matching, providing deeper insights into their connections and optimal ways to combine them.
The trend towards hybrid models underscores a growing understanding that the optimal generative solution is often task-dependent and may involve drawing upon a toolkit of different mechanisms rather than adhering strictly to a single monolithic approach.
Prominent Applications of Latent Diffusion Models
LDMs have become particularly dominant in visual content generation and are increasingly finding use in scientific domains.
Image Synthesis: This is arguably the flagship application of LDMs. Models like Stable Diffusion and DALL-E 2 (which incorporates diffusion principles) are capable of generating exceptionally high-quality and diverse images from textual descriptions (text-to-image synthesis).
Image Editing, Inpainting, and Outpainting: LDMs are highly effective at modifying existing images. This includes editing regions based on text prompts, filling in missing parts of an image (inpainting), or extending an image beyond its original boundaries (outpainting).
Video Generation: The principles of LDMs are being extended to the temporal domain for video generation, with Diffusion Transformers showing promise in text-to-video tasks.
Scientific Applications: LDMs are making inroads into scientific discovery. For example, AlphaFold3, a state-of-the-art model for protein structure prediction, is described as a diffusion model. In medicine, PathLDM demonstrates text-conditioned generation of histopathology images, aiding in computational pathology.
Digital Media and Creative Industries: LDMs are widely used by artists and designers for rapidly generating concept art, storyboards, illustrations, and other visual assets for films, video games, and marketing.
Diverse Applications of Conditional Flow Matching
CFM’s efficiency and flexibility have enabled its rapid adoption across a broader range of modalities and problem types beyond traditional image synthesis.
Image and Video Generation: CFM models are competitive with diffusion models in terms of image and video quality and are often significantly faster in training and inference.
Audio and Music Generation: CFM has shown strong performance in the audio domain. MusFlow enables multimodal music generation from inputs like images, stories, and text captions. Other applications include voice conversion (e.g., StableVC) and real-time text-to-speech synthesis (e.g., Matcha-TTS, VoiceFlow).
Robotics: CFM is being applied to learn robot trajectories and policies. It can generate smooth, dynamically feasible motion plans and control policies, with examples like FlowNav for navigation and the action generation component in HybridVLA.
Scientific Modeling and Simulation: CFM’s ability to model continuous transformations is valuable in science and engineering. Applications include modeling the temporal evolution of material microstructures (often with unpaired conditioning data via CVFM), simulating 2D Darcy flow for porous media, reconstructing near-wall turbulence fields in fluid dynamics, and generating protein backbone structures.
Missing Data Imputation: The CFMI (Conditional Flow Matching for Imputation) method leverages CFM to impute missing values in tabular and time-series datasets, outperforming traditional and other deep learning-based imputation techniques.
Language Modeling and Neural Training Dynamics: CFM is being explored for applications in language modeling and even for modeling the dynamics of neural network training itself (e.g., Gradient Flow Matching).
Tabular Data Generation: CFM techniques are also being used for generating synthetic tabular data, which can be useful for data augmentation or privacy-preserving data sharing.
The rapid diversification of CFM into non-visual domains such as audio, robotics, scientific modeling, and tabular data suggests that it may offer a more inherently generalizable framework for learning continuous transformations across arbitrary data types. While LDMs have achieved unparalleled success in vision, their architecture (image-specific VAEs, convolutional U-Nets) is tightly coupled with visual data structures. In contrast, the core principle of CFM—learning a generic vector field 
Furthermore, the application of CFM to “meta-learning” tasks, such as modeling the entire training trajectory of neural network weights (as in Gradient Flow Matching) or forecasting complex system trajectories, indicates a significant conceptual extension. CFM is not only being used to generate static data instances but also to model the processes and dynamics of complex systems themselves. This represents a higher level of abstraction, opening avenues for CFM in control theory, system identification, and even for gaining a deeper understanding of learning processes. This is a domain where LDMs are less commonly applied directly, highlighting another dimension of CFM’s expanding utility.
Comparative Suitability for Different Generative Tasks
The choice between LDM and CFM often depends on the specific requirements of the generative task:
LDMs are generally the go-to choice for high-fidelity visual content generation where achieving maximum sample diversity is paramount, and where large, often paired, datasets (like image-text pairs) are available for training. Their strong performance in text-to-image synthesis has made them a staple in creative AI.
CFM demonstrates particular strengths in scenarios where:
Speed is critical: Both for training and, especially, for inference.
Diverse data modalities beyond vision are targeted (e.g., audio, robotics trajectories, scientific data).
Complex or unpaired conditioning is involved, as CVFM can handle continuous, unpaired conditioning variables prevalent in scientific experiments or industrial processes.
Direct trajectory control or modeling of dynamics is beneficial, such as in robotics, physical process simulation, or data imputation over time.
Looking ahead, several research directions and unresolved challenges will likely shape the future of these models:
Improving LDMs: Further research into mitigating VAE-induced information loss, perhaps through better VAE architectures or alternative compression strategies. Making LDMs inherently more robust to adversarial attacks and input perturbations also remains crucial.
Sophisticated Hybridization: Designing more deeply integrated and adaptive hybrid architectures that can dynamically leverage the strengths of both stochastic refinement and deterministic flow-based generation.
Broader Data Types: Extending CFM and potentially LDM-like principles more effectively to discrete, structured, or graph-based data.
Controllability and Interpretability: A major overarching challenge for all powerful generative models is achieving true, fine-grained, and reliable controllability over the semantic attributes of generated samples, coupled with a deeper understanding of why a model produces a specific output. While conditioning mechanisms are advancing, moving beyond pattern generation to genuinely interpretable and causally controllable synthesis remains a significant frontier. As these models become more deeply embedded in critical applications, the demand for transparency, debuggability, and robust semantic control will only intensify.
Reference:
- An Introduction to Flow Matching and Diffusion Models, accessed on June 12, 2025, https://diffusion.csail.mit.edu/docs/lecture-notes.pdf
- Flow Matching and Diffusion Models, accessed on June 12, 2025, https://diffusion.csail.mit.edu/
- Boosting Latent Diffusion with Flow Matching – arXiv, accessed on June 12, 2025, https://arxiv.org/html/2312.07360v1
- On the Robustness of Latent Diffusion Models – arXiv, accessed on June 12, 2025, https://arxiv.org/html/2306.08257
- Everything You Need To Know About Stable Diffusion – Hyperstack, accessed on June 12, 2025, https://www.hyperstack.cloud/blog/case-study/everything-you-need-to-know-about-stable-diffusion
- Stable Diffusion – Wikipedia, accessed on June 12, 2025, https://en.wikipedia.org/wiki/Stable_Diffusion
- NeurIPS Tutorial Flow Matching for Generative Modeling, accessed on June 12, 2025, https://neurips.cc/virtual/2024/tutorial/99531
- A Visual Dive into Conditional Flow Matching | ICLR Blogposts 2025, accessed on June 12, 2025, https://dl.heeere.com/conditional-flow-matching/blog/conditional-flow-matching/
- FLOW MATCHING FOR GENERATIVE MODELING – OpenReview, accessed on June 12, 2025, https://openreview.net/pdf/e99034416acd1ca82991f5d63735e77130fc06a7.pdf
- How do you train a latent diffusion model compared to standard ones? – Milvus, accessed on June 12, 2025, https://milvus.io/ai-quick-reference/how-do-you-train-a-latent-diffusion-model-compared-to-standard-ones
- Reconstruction vs. Generation: Taming Optimization Dilemma in Latent Diffusion Models, accessed on June 12, 2025, https://arxiv.org/html/2501.01423v1
- Conditional Variable Flow Matching: Transforming Conditional Densities with Amortized Conditional Optimal Transport – arXiv, accessed on June 12, 2025, https://arxiv.org/html/2411.08314v4
- Conditional Variable Flow Matching: Transforming Conditional Densities with Amortized Conditional Optimal Transport – arXiv, accessed on June 12, 2025, https://arxiv.org/html/2411.08314v1
- Flow Matching Explained: From Noise to Robot Actions | Federico …, accessed on June 12, 2025, https://federicosarrocco.com/blog/flow-matching
- Scene Graph Conditioning in Latent Diffusion – arXiv, accessed on June 12, 2025, https://arxiv.org/html/2310.10338
- MusFlow: Multimodal Music Generation via Conditional Flow … – arXiv, accessed on June 12, 2025, https://arxiv.org/abs/2504.13535
- Introduction to Diffusion Models for Machine Learning – AssemblyAI, accessed on June 12, 2025, https://www.assemblyai.com/blog/diffusion-models-for-machine-learning-introduction
- An Introduction to Diffusion Models and Stable Diffusion – Marvik – Blog, accessed on June 12, 2025, https://blog.marvik.ai/2023/11/28/an-introduction-to-diffusion-models-and-stable-diffusion/
- Step-by-step guide to implement latent diffusion – Kaggle, accessed on June 12, 2025, https://www.kaggle.com/code/deveshsurve/step-by-step-guide-to-implement-latent-diffusion
- arxiv.org, accessed on June 12, 2025, https://arxiv.org/html/2310.12004v3#:~:text=Nevertheless%2C%20there%20are%20two%20major,scale%20of%20the%20diffusion%20model.
- Power of Latent Diffusion Models: Revolutionizing Image Creation – – Analytics Vidhya, accessed on June 12, 2025, https://www.analyticsvidhya.com/blog/2023/01/power-of-latent-diffusion-models-revolutionizing-image-creation/
- PathLDM: Text Conditioned Latent Diffusion Model for Histopathology – CVF Open Access, accessed on June 12, 2025, https://openaccess.thecvf.com/content/WACV2024/papers/Yellapragada_PathLDM_Text_Conditioned_Latent_Diffusion_Model_for_Histopathology_WACV_2024_paper.pdf
- [2503.09419] Alias-Free Latent Diffusion Models:Improving Fractional Shift Equivariance of Diffusion Latent Space – arXiv, accessed on June 12, 2025, https://arxiv.org/abs/2503.09419
- Efficient Flow Matching using Latent Variables – arXiv, accessed on June 12, 2025, https://arxiv.org/html/2505.04486v2
- Conditional Flow Matching Loss (CFM) – Emergent Mind, accessed on June 12, 2025, https://www.emergentmind.com/topics/conditional-flow-matching-loss
- Flow Matching: Matching flows instead of scores – Jakub M. Tomczak, accessed on June 12, 2025, https://jmtomczak.github.io/blog/18/18_fm.html
- atong01/conditional-flow-matching: TorchCFM: a … – GitHub, accessed on June 12, 2025, https://github.com/atong01/conditional-flow-matching
- Flow Matching for Generative Modeling | TransferLab — appliedAI Institute, accessed on June 12, 2025, https://transferlab.ai/pills/2024/flow-matching/
- Elucidating the Design Choice of Probability Paths in Flow Matching for Forecasting, accessed on June 12, 2025, https://openreview.net/forum?id=6Ire5JaobL
- What is the difference between a stochastic differential equation and an ODE? – Quora, accessed on June 12, 2025, https://www.quora.com/What-is-the-difference-between-a-stochastic-differential-equation-and-an-ODE
- What phenomena are better modelled by SDE instead of ODE? – MathOverflow, accessed on June 12, 2025, https://mathoverflow.net/questions/460603/what-phenomena-are-better-modelled-by-sde-instead-of-ode
- Conditional flow matching for generative modeling of near-wall turbulence with quantified uncertainty – arXiv, accessed on June 12, 2025, https://arxiv.org/html/2504.14485v1
- Boosting Latent Diffusion with Flow Matching – arXiv, accessed on June 12, 2025, https://arxiv.org/html/2312.07360v2
- Flow Matching Models (FM) – Emergent Mind, accessed on June 12, 2025, https://www.emergentmind.com/topics/flow-matching-models
- HybridVLA: Collaborative Diffusion and Autoregression in a Unified Vision-Language-Action Model – arXiv, accessed on June 12, 2025, https://arxiv.org/html/2503.10631v1
- Local Flow Matching Generative Models – arXiv, accessed on June 12, 2025, https://arxiv.org/html/2410.02548v2
- FlowMP: Learning Motion Fields for Robot Planning with Conditional Flow Matching – arXiv, accessed on June 12, 2025, https://arxiv.org/html/2503.06135v1
- [2506.09258] CFMI: Flow Matching for Missing Data Imputation – arXiv, accessed on June 12, 2025, http://www.arxiv.org/abs/2506.09258
- Gradient Flow Matching for Learning Update Dynamics in Neural Network Training – arXiv, accessed on June 12, 2025, https://arxiv.org/html/2505.20221v1