Singular Value Decomposition (SVD) is a powerful matrix decomposition technique that generalizes the concept of eigenvalue decomposition to non-square matrices. Eigenvalue decomposition specifically decomposes a square matrix into its constituent eigenvalues and eigenvectors. This decomposition is particularly valuable because it reveals fundamental properties of the linear transformation represented by the matrix. Eigenvalues tell us how the transformation scales along certain directions, while eigenvectors represent those directions.
In SVD, any 
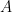
1. Left Singular Vectors (U): An 
2. Singular Values ($latex\Sigma$): An
3. **Right Singular Vectors (

Sure, here’s a simple Python code snippet using the NumPy library to demonstrate how to perform dimensionality reduction using Singular Value Decomposition (SVD):
import numpy as np
# Generate random data matrix (replace with your own data)
data = np.random.rand(100, 20) # 100 samples, 20 features
# Perform Singular Value Decomposition (SVD)
U, s, Vt = np.linalg.svd(data, full_matrices=False)
# Choose number of dimensions to reduce to
k = 10
# Reduce dimensions
reduced_data = np.dot(U[:, :k], np.diag(s[:k]))
# Display original and reduced data shapes
print(“Original data shape:”, data.shape)
print(“Reduced data shape:”, reduced_data.shape)
This code snippet does the following:
1. Imports the NumPy library.
2. Generates random data as a matrix (data).
3. Performs Singular Value Decomposition (SVD) on the data matrix using np.linalg.svd(), obtaining the matrices 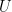
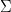

4. Chooses the number of dimensions to reduce to (k).
5. Reduces the dimensions of the data by selecting the first k columns of
6. Prints the shapes of the original and reduced data matrices.
You can adjust the `data` matrix to use your own dataset, and modify the value of `k` to specify the desired reduced dimensionality.
Here’s the equivalent code in R
# Generate random data matrix (replace with your own data)
set.seed(123) # For reproducibility
data <- matrix(runif(100*20), nrow=100, ncol=20) # 100 samples, 20 features
# Perform Singular Value Decomposition (SVD)
svd_result <- svd(data)
# Choose number of dimensions to reduce to
k <- 10
# Reduce dimensions
reduced_data <- svd_result$u[, 1:k] %*% diag(svd_result$d[1:k])
# Display original and reduced data dimensions
cat(“Original data dimension:”, dim(data), “\n”)
cat(“Reduced data dimension:”, dim(reduced_data), “\n”)
Discover more from Science Comics
Subscribe to get the latest posts sent to your email.
