

Subscribe to get access
Read more of this content when you subscribe today.
Principal Component Analysis (PCA) is a statistical technique used for dimensionality reduction, which simplifies the complexity in high-dimensional data while retaining important infomation. The basic idea of this method is to transform a large set of variables into a smaller one that retain most of the variation in the large set. It does this by identifying the directions (principal components) in which the variance of the data is maximal, allowing for simplification while retaining essential patterns and trends. It’s widely used in fields such as machine learning, data analysis, and image processing.
There are two ways to compute the principal components in PCA: the first method involves the eigenvalue decomposition of the covariance matrix, which identifies the directions of maximum variance in the data, while the second method utilizes singular value decomposition (SVD), a mathematical technique that efficiently reveals the underlying structure of the dataset by decomposing the data matrix itself. Let’s dig into both of them.
Steps in PCA based on the Covariance Matrix:
- Standardize the Data:
- Compute the Covariance Matrix:
whereis a data vector,
is the mean vector, and
is the number of samples.
- Calculate the Eigenvalues and Eigenvectors:


- Solve the equation:
whereis the covariance matrix,
is an eigenvector, and
is its corresponding eigenvalue.

Sort Eigenvalues and Eigenvectors: Organize the eigenvalues in descending order and sort the eigenvectors accordingly.
Select Principal Components: Choose the top k eigenvectors. These vectors form a matrix 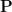


Transform the Data: Project the original dataset 


Steps to Perform PCA based SVD of the input matrix:
Center the Data: Subtract the mean of each column from the dataset $latexX$ to center the data around zero. This ensures that the principal components describe the variance rather than the mean.

Perform SVD:
Using the centered matrix $latexX_{\text{centered}}$, perform Singular Value Decomposition:

: Orthogonal matrix of left singular vectors.
: Diagonal matrix of singular values.
: Orthogonal matrix of right singular vectors (the principal directions).
Principal Components:
- The columns of
(or rows of
).
- The singular values in
Projection onto Principal Components:
- The data can be projected onto the principal components by multiplying the centered data with
:

Here 
Variance Explained:
- The variance explained by each principal component is proportional to the square of its corresponding singular value:
whereare the singular values from

Which one to choose?
In summary, there are two ways to compute the principal components in PCA: the first method involves the eigenvalue decomposition of the covariance matrix, which identifies the directions of maximum variance in the data, while the second method utilizes singular value decomposition (SVD), a mathematical technique that efficiently reveals the underlying structure of the dataset by decomposing the data matrix itself.
So, when the number of samples is much bigger than the number of features, it’s maybe faster and less computational expensive to use PCA based on the covariance matrix. Otherwise, it’s better to use SVD. This will be further explored in the solver option of the Python implementation of PCA in sklearn below.
Python Implementation
You can use the scikit-learn library to perform PCA in Python. Here’s a step-by-step example:
Got it! Here’s the code with explanations placed before each section and without using any headers:
First, we need to import the necessary libraries:
import numpy as np
import pandas as pd
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
import matplotlib.pyplot as pltWe create some sample data:
np.random.seed(0)
data = np.random.rand(100, 3) # 100 samples with 3 featuresNext, we standardize the data to have a mean of 0 and a standard deviation of 1 (this is important as PCA is a sensitive girl ?):
scaler = StandardScaler()
scaled_data = scaler.fit_transform(data)We then perform Principal Component Analysis (PCA) to reduce the data to 2 principal components:
pca = PCA(n_components=2)
principal_components = pca.fit_transform(scaled_data)We create a DataFrame from the principal components, with columns labeled ‘PC1’ and ‘PC2’:
principal_df = pd.DataFrame(data=principal_components, columns=['PC1', 'PC2'])To visualize the principal components, we create a scatter plot:
plt.figure(figsize=(8, 6))
plt.scatter(principal_df['PC1'], principal_df['PC2'])
plt.xlabel('Principal Component 1')
plt.ylabel('Principal Component 2')
plt.title('2 component PCA')
plt.show()Finally, we print the explained variance ratio to understand how much variance each principal component captures:
print(f"Explained variance ratio: {pca.explained_variance_ratio_}")Combined code:
import numpy as np
import pandas as pd
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
# Sample data creation
np.random.seed(0)
data = np.random.rand(100, 3) # 100 samples with 3 features
# Standardize the data
scaler = StandardScaler()
scaled_data = scaler.fit_transform(data)
# Perform PCA
pca = PCA(n_components=2)
principal_components = pca.fit_transform(scaled_data)
# Create a DataFrame with the principal components
principal_df = pd.DataFrame(data=principal_components, columns=['PC1', 'PC2'])
# Plot the principal components
plt.figure(figsize=(8, 6))
plt.scatter(principal_df['PC1'], principal_df['PC2'])
plt.xlabel('Principal Component 1')
plt.ylabel('Principal Component 2')
plt.title('2 component PCA')
plt.show()
# Explained variance
print(f"Explained variance ratio: {pca.explained_variance_ratio_}")Note that: The svd_solver has a few options: {‘auto’, ‘full’, ‘covariance_eigh’, ‘arpack’, ‘randomized’}. The default option is ‘auto’, which means:
- Small Data with Many Samples: If your data has fewer than 1000 features (columns) and more than 10 times as many samples (rows), the algorithm uses the “covariance_eigh” solver. This method is efficient for such cases.
- Large Data: If your dataset is bigger than 500×500 and you want to extract fewer than 80% of the smallest dimension (either rows or columns), the algorithm uses the “randomized” method, which is faster and suitable for large datasets.
- Other Cases: For all other scenarios, the algorithm computes the full Singular Value Decomposition (SVD) and might truncate the results afterward. This is an exact method but can be slower for very large datasets.
But you can choose the solver to select the PCA approach that you want to use.

Implementation to retain 95% of the variance:
We can update the codes to retain 95% of the variance. To do that, you need to adjust the PCA implementation to automatically select the number of components that capture at least 95% of the total variance:
# Perform PCA to retain 95% of variance
pca = PCA(n_components=0.95)R Implementation
You can use the prcomp function to perform PCA in R. Here’s a step-by-step example:
First, we set the seed for the random number generator to ensure reproducibility. We then create a matrix of 300 random numbers, arranged into 100 rows and 3 columns, representing 100 samples with 3 features each:
set.seed(0)
data <- matrix(runif(300), nrow=100, ncol=3) # 100 samples with 3 featuresWe standardize the data so that each feature has a mean of 0 and a standard deviation of 1, which is important for PCA:
data_scaled <- scale(data)We perform Principal Component Analysis (PCA) on the standardized data, ensuring it is centered and scaled during the process:
pca <- prcomp(data_scaled, center = TRUE, scale. = TRUE)To create a data frame containing the first two principal components, we extract these components from the PCA result and label the columns accordingly:
principal_components <- data.frame(pca$x[,1:2])
colnames(principal_components) <- c("PC1", "PC2")Next, we load the ggplot2 library and use it to create a scatter plot of the principal components. This helps visualize the data in a reduced dimension:
library(ggplot2)
ggplot(principal_components, aes(x = PC1, y = PC2)) +
geom_point() +
ggtitle("2 component PCA") +
xlab("Principal Component 1") +
ylab("Principal Component 2")Finally, we calculate the explained variance ratio for each principal component to understand how much variance each component captures, and then print these values.
explained_variance <- pca$sdev^2 / sum(pca$sdev^2)
print(explained_variance)Combined codes:
# Sample data creation
set.seed(0)
data <- matrix(runif(300), nrow=100, ncol=3) # 100 samples with 3 features
# Standardize the data
data_scaled <- scale(data)
# Perform PCA
pca <- prcomp(data_scaled, center = TRUE, scale. = TRUE)
# Create a data frame with the principal components
principal_components <- data.frame(pca$x[,1:2])
colnames(principal_components) <- c("PC1", "PC2")
# Plot the principal components
library(ggplot2)
ggplot(principal_components, aes(x = PC1, y = PC2)) +
geom_point() +
ggtitle("2 component PCA") +
xlab("Principal Component 1") +
ylab("Principal Component 2")
# Explained variance
explained_variance <- pca$sdev^2 / sum(pca$sdev^2)
print(explained_variance)Implementation to retain 95% of the variance:
You can also modify the R code to retain 95% of the variance:
# Sample data creation
set.seed(0)
data <- matrix(runif(300), nrow=100, ncol=3) # 100 samples with 3 features
# Standardize the data
data_scaled <- scale(data)
# Perform PCA
pca <- prcomp(data_scaled, center = TRUE, scale. = TRUE)
# Determine the number of components to retain 95% of the variance
explained_variance <- pca$sdev^2 / sum(pca$sdev^2)
cumulative_variance <- cumsum(explained_variance)
num_components <- which(cumulative_variance >= 0.95)[1]
# Create a data frame with the selected principal components
principal_components <- data.frame(pca$x[, 1:num_components])
colnames(principal_components) <- paste0("PC", 1:num_components)
# Plot the principal components
library(ggplot2)
ggplot(principal_components, aes_string(x = colnames(principal_components)[1], y = colnames(principal_components)[2])) +
geom_point() +
ggtitle("PCA with 95% Variance Retained") +
xlab("Principal Component 1") +
ylab("Principal Component 2")
# Explained variance and number of components
print(explained_variance)
print(paste("Number of components selected:", num_components))Discover more from Science Comics
Subscribe to get the latest posts sent to your email.