Subscribe to get access
??Subscribe to read the rest of the comics, the fun you can’t miss ??
Ridge regression:
Ridge adds the 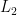
where 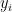


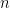
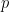
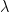

Choosing Between Lasso and Ridge:
- Lasso: Preferred when you expect only a few features to be important. It performs feature selection and yields simpler models.
- Ridge: Preferred when you expect many features to contribute to the outcome. It helps in managing multicollinearity and maintaining all features in the model.
Implementation:
In the following codes, we will follow these steps:
- Import/Load Packages: Necessary packages are imported or installed (
glmnet,caret,e1071for R;numpy,matplotlib,scikit-learnfor Python). - Load Dataset: Synthetic datasets are created with 100 samples and 20 features.
- Split Dataset: The datasets are split into training and test sets.
- Train Ridge Model: Ridge regression models are trained using
cv.glmnetfor R andRidgefor Python. - Evaluate Model: The model’s performance is evaluated using mean squared error (MSE) and R² score.
- Visualize Results: Coefficients of the Ridge model are plotted to visualize the effect of L2 regularization on the feature coefficients.
Python Code:
# Step 1: Import the necessary libraries
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_regression
from sklearn.model_selection import train_test_split
from sklearn.linear_model import Ridge
from sklearn.metrics import mean_squared_error, r2_score
# Step 2: Load the dataset (using a synthetic dataset for this example)
X, y = make_regression(n_samples=100, n_features=20, noise=0.1, random_state=42)
# Step 3: Split the dataset into training and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Step 4: Train the Ridge regression model
alpha = 1.0 # Regularization strength
ridge = Ridge(alpha=alpha)
ridge.fit(X_train, y_train)
# Step 5: Evaluate the model
y_train_pred = ridge.predict(X_train)
y_test_pred = ridge.predict(X_test)
print("Training set evaluation:")
print("Mean Squared Error:", mean_squared_error(y_train, y_train_pred))
print("R^2 Score:", r2_score(y_train, y_train_pred))
print("\nTest set evaluation:")
print("Mean Squared Error:", mean_squared_error(y_test, y_test_pred))
print("R^2 Score:", r2_score(y_test, y_test_pred))
# Step 6: Visualize the results (if applicable, here we'll plot the coefficients)
plt.figure(figsize=(10, 6))
plt.plot(ridge.coef_, marker='o', linestyle='none')
plt.title('Ridge Regression Coefficients')
plt.xlabel('Feature Index')
plt.ylabel('Coefficient Value')
plt.grid(True)
plt.show()R Code
# Step 1: Install and load the necessary packages
install.packages("glmnet")
install.packages("caret")
install.packages("e1071")
library(glmnet)
library(caret)
library(e1071)
# Step 2: Load the dataset (using a synthetic dataset for this example)
set.seed(42)
n <- 100
p <- 20
X <- matrix(rnorm(n * p), n, p)
beta <- rnorm(p)
y <- X %*% beta + rnorm(n) * 0.1
# Step 3: Split the dataset into training and test sets
trainIndex <- createDataPartition(y, p = 0.8, list = FALSE)
X_train <- X[trainIndex, ]
X_test <- X[-trainIndex, ]
y_train <- y[trainIndex]
y_test <- y[-trainIndex]
# Step 4: Train the Ridge regression model
alpha <- 0 # Ridge regression (L2 penalty)
ridge_model <- cv.glmnet(X_train, y_train, alpha = alpha)
# Step 5: Evaluate the model
y_train_pred <- predict(ridge_model, X_train, s = "lambda.min")
y_test_pred <- predict(ridge_model, X_test, s = "lambda.min")
train_mse <- mean((y_train - y_train_pred)^2)
test_mse <- mean((y_test - y_test_pred)^2)
train_r2 <- 1 - sum((y_train - y_train_pred)^2) / sum((y_train - mean(y_train))^2)
test_r2 <- 1 - sum((y_test - y_test_pred)^2) / sum((y_test - mean(y_test))^2)
cat("Training set evaluation:\n")
cat("Mean Squared Error:", train_mse, "\n")
cat("R^2 Score:", train_r2, "\n")
cat("\nTest set evaluation:\n")
cat("Mean Squared Error:", test_mse, "\n")
cat("R^2 Score:", test_r2, "\n")
# Step 6: Visualize the results (if applicable, here we'll plot the coefficients)
ridge_coefficients <- coef(ridge_model, s = "lambda.min")
plot(ridge_coefficients, main = "Ridge Regression Coefficients", xlab = "Feature Index", ylab = "Coefficient Value", pch = 16, col = "blue")Discover more from Science Comics
Subscribe to get the latest posts sent to your email.
