Now hypothesis testing is basically the science of making decisions based on evaluating the likelihood of an event.
In simple words, it is like if the null hypothesis 
So in the previous section, we have talked about how to use critical values to conduct hypothesis testing. Critical values help one see if
In this section, we will talk about hypothesis testing using p-values. A p-value, short for “probability value,” is a statistical measure that helps us quantify the probability of obtaining results as extreme as or more extreme than the observed results when the null hypothesis is true.
The procedure of hypothesis using p-values is not too different from using critical values:
- Formulate hypotheses:
- Null Hypothesis (Ho): This is the default or status quo hypothesis. It typically represents no effect or no difference.
- Alternative Hypothesis (HA): This is the hypothesis you want to test, often suggesting an effect or a difference.
- Collect data and perform a statistical test, such as a t-test or chi-squared test, depending on the nature of the data and the research question.
- Set the significance level
.
- Calculate the p-value: The p-value is calculated by the statistical test, and it represents the probability of observing data as extreme as or more extreme than the observed data if the null hypothesis is true. A small p-value suggests that the observed results are unlikely to have occurred by chance, while a larger p-value suggests that the results are more consistent with the null hypothesis. If the p-value is less than or equal to the chosen significance level (alpha), one can reject the null hypothesis in favor of the alternative hypothesis. If the p-value is greater than alpha, the null hypothesis is not rejected.
Recall that a p-value quantifies the probability of obtaining results as extreme as or more extreme than the observed results when the null hypothesis is true. Therefore, a smaller p-value (e.g., 
Now let’s dig into the details by reusing the examples in the previous section!
Fat in ground meat
Let’s recall the problem, which is as follows: I randomly bought 35 packages of meat from local stores and brought them home to scan. After calculating, I found that the sample mean of fat in each package is 

The test procedure:
Now let’s conduct a hypothesis-testing procedure using the p-value.
Here the sample size is 
First, to set the null and alternate hypothesis, note that 3% of 200 grams is 6 grams. Therefore my null hypothesis is

because I want to reject the fact that on average the packages contain 3% of fat. I think the packages contain more than 3% on average. Therefore my alternative hypothesis is
The test statistic is

Again, I choose the significance level
Now we calculate the p-value which represents the probability of observing data as extreme as or more extreme than the observed data if the null hypothesis is true. Since the alternative hypothesis is 

In this case, let 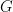

So the p-value is smaller than 
However, note that if we chose the significance level 

The Weight of Chocolate Bars
Imagine you work at a chocolate factory and are responsible for ensuring chocolate bars’ quality. The factory claims that their chocolate bars have an average weight of 100 grams. However, you suspect that some of the machines might be overfilling the bars.
Your null hypothesis (

To test this, you randomly sample 30 chocolate bars and find that they have an average weight of
and the sample standard deviation is


So to write everything in math terms, the null hypothesis is
because I want to reject the fact that on average each chocolate bar weighs 100 grams. I think each bar weighs more than 100 grams on average. Therefore, my alternative hypothesis is
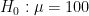

Now let us pick our significance level to be 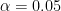

The test statistic is


In Figure 3 above, the orange dot region is the critical region (rejection region), which contains the values that should not happen if the null hypothesis is true. The critical value is the value that separates the normal region and the rejection region. Here by the normal region I mean the region where 

Therefore we reject the null hypothesis and conclude that on average each bar weighs more than 100 grams. Okay! That’s good for … the customers – the ones who don’t even know that they are lucky!

Discover more from Science Comics
Subscribe to get the latest posts sent to your email.