The term “Student’s distribution,” also known as the “t-distribution,” is a probability distribution that arises in statistics and is used in hypothesis testing and confidence interval estimation. It is named after the statistician William Sealy Gosset, who published under the pseudonym “Student” because he was working for the Guinness Brewery and was not allowed to publish his work under his real name.
The t-distribution is similar in shape to the normal distribution but has heavier tails, which makes it suitable for situations where the sample size is small and the population standard deviation is unknown. It is commonly used in cases where you are dealing with small samples and need to make inferences about the population mean.
Specifically, suppose that we have a sample of 
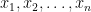


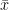
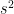
and


Then the t-statistic given by
follows a Student’s t-distribution with 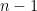


The key characteristics of the t-distribution include:
– Bell-shaped: Like the normal distribution, it is bell-shaped, symmetric, and unimodal.
Shape Parameter: The shape of the t-distribution is determined by a parameter called “degrees of freedom” (df). The degrees of freedom are usually associated with the sample size. The larger the sample size, the closer the t-distribution approximates the normal distribution.
– Heavier Tails: As the degrees of freedom decrease, the t-distribution has heavier tails compared to the normal distribution. This means that it allows for more variability in the data, especially in the tails.
– Central Limit Theorem: When the sample size is sufficiently large (typically around 30 or more), the t-distribution approaches the normal distribution.
The t-distribution is commonly used in statistical analysis when you are working with small sample sizes and need to calculate confidence intervals or perform hypothesis tests, such as t-tests, to determine whether the means of two groups are significantly different. It is a fundamental tool in inferential statistics.
Example of singing fish
You are a marine biologist studying the singing abilities of a particular species of fish known as the “Melodious Minnows.” You have heard legends that these fish can sing at an average pitch of 440 Hz (the standard pitch for tuning musical instruments, known as “concert A”). You decide to test this claim scientifically.
Hypothesis
- Null Hypothesis: The average singing pitch of Melodious Minnows is 440 Hz.
- Alternative Hypothesis: The average singing pitch of Melodious Minnows is different from 440 Hz.
Data Collection
You gather a sample of Melodious Minnows and record their singing pitches:
- Singing pitches (in Hz): 442, 438, 445, 441, 439, 437, 443, 440, 444, 439
Perform One-Sample t-test
# Sample data
pitches <- c(442, 438, 445, 441, 439, 437, 443, 440, 444, 439)
# Population mean (legendary average pitch)
population_mean <- 440
# Perform one-sample t-test
t_test_result <- t.test(pitches, mu = population_mean)
print(t_test_result)Explanation
- pitches: This vector contains the singing pitches of the sampled Melodious Minnows.
- population_mean: This is the legendary average singing pitch, set to 440 Hz.
- t.test(): The function performs a one-sample t-test to compare the sample mean to the population mean.
Result Interpretation
The result of the t-test will tell you whether there is a statistically significant difference between the average pitch of your sample of Melodious Minnows and the legendary 440 Hz.
So, if you run this test, you might end up with something like:
One Sample t-test
data: pitches
t = 1.4142, df = 9, p-value = 0.191
alternative hypothesis: true mean is not equal to 440
95 percent confidence interval:
438.35 443.45
sample estimates:
mean of x
440.9In this hypothetical result:
- The p-value is 0.191, which is greater than 0.05, indicating that the difference is not statistically significant.
- The mean of the sample (440.9 Hz) is very close to the legendary pitch, so it looks like the legends might be true after all!
Independent samples
In hypothesis testing, independent samples refer to two or more groups or sets of data points that are unrelated to each other, meaning that the values or observations in one sample are not dependent on or influenced by the values in the other sample. The independence of samples is a fundamental assumption in many statistical tests, such as t-tests and analysis of variance (ANOVA).
For example, if you are comparing the test scores of two different groups of students (e.g., Group A and Group B), and the scores of students in Group A are in no way related to or affected by the scores in Group B, you can consider these samples as independent.
The concept of independence is essential because it helps ensure that the statistical test’s results are valid and that any differences or relationships observed between the samples are not due to some form of dependence or interaction between them. If the samples are not independent, different statistical methods, such as paired tests or repeated measures analysis, may be more appropriate for the analysis.
Discover more from Science Comics
Subscribe to get the latest posts sent to your email.