Model ensembling is a machine learning technique where multiple models are combined to improve the overall performance compared to individual models. The main idea is that different models might capture different patterns in the data, and by combining their predictions, you can reduce the likelihood of errors and improve generalization to unseen data.
Types of Ensembles
- Bagging (Bootstrap Aggregating): Multiple instances of the same model type are trained on different bootstraps of the data, often generated by resampling with replacement. The most common example is the Random Forest algorithm, which is an ensemble of decision trees.
- Boosting: Models are trained sequentially, where each new model attempts to correct the errors made by the previous models. Examples include AdaBoost, Gradient Boosting Machines (GBM), and XGBoost.
- Stacking: Different types of models are trained on the same dataset, and their outputs are then combined using a meta-model that makes the final prediction. The meta-model learns how to best combine the predictions of the individual models.
- Voting: In a voting ensemble, multiple models (often of different types) are trained, and their predictions are combined by a majority vote (for classification) or averaging (for regression).
When we combine multiple models in an ensemble, especially through techniques like bagging, we can reduce the variance without necessarily increasing the bias.
Mathematical Intuition Behind Variance Reduction in Bagging
Let’s assume that we have an ensemble of models. Consider 
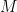

If each model 
![E[f_i(x)]](https://s0.wp.com/latex.php?latex=E%5Bf_i%28x%29%5D+&bg=ffffff&fg=000&s=0&c=20201002)

Next, note that the models in bagging are trained independently on different bootstraps of the data


Ensemble methods often lead to higher accuracy because they leverage the strengths of different models. However, ensembling many models can also be complex and computationally expensive. Also, the combination of many models can make it harder to interpret the final predictions, which is a concern in fields requiring model transparency.
Discover more from Science Comics
Subscribe to get the latest posts sent to your email.