The paper “DPER: Direct Parameter Estimation for Randomly Missing Data,” by Thu Nguyen, Khoi Minh Nguyen-Duy, Duy Ho Minh Nguyen, Binh T. Nguyen, Bruce Alan Wade introduces a novel methodology for handling missing data. Its main contributions are as follows:
- Direct Parameter Estimation: The authors propose algorithms to compute Maximum Likelihood Estimates (MLEs) for the mean and covariance matrix directly from data with randomly missing values. This eliminates the need for iterative imputation techniques, which are computationally expensive and sometimes less reliable.
- Applicability Across Data Sizes: The proposed algorithms are effective for both small and large datasets, making them versatile and practical for various real-world applications.
- Robust Assumptions: The methodology requires only a mild assumption of bivariate normality for pairs of features rather than the stricter multivariate normality assumption. This enhances the algorithm’s robustness and usability across a wider range of datasets.
- Empirical Superiority: Experiments show that the proposed approach often outperforms state-of-the-art imputation-based methods in terms of both speed and accuracy, especially as the missing data rate increases.
- Efficiency: The direct computation strategy avoids multiple iterations, making it computationally efficient and particularly suitable for scenarios with high-dimensional data and a large number of missing entries.
These contributions position the DPER algorithm as a robust and efficient alternative to traditional methods for parameter estimation in datasets with missing values.
Methodology
The basic idea of the DPER (Direct Parameter Estimation for Randomly Missing Data) algorithm is to compute the Maximum Likelihood Estimates (MLEs) of the mean and covariance matrix directly from datasets with missing values, without requiring imputation. Here’s a breakdown of the algorithm’s core concepts and ideas:
Key Principles:
- Pairwise Feature Estimation:
- Instead of handling all features simultaneously (which is computationally challenging for missing data), DPER estimates parameters (mean and covariance) based on pairs of features.
- Each pair of features is assumed to follow a bivariate normal distribution (a much milder assumption compared to multivariate normality).
- Direct Computation:
- The algorithm derives closed-form formulas or optimization steps to estimate the mean and covariance directly from the available data in each feature pair.
- Missing entries in the data are naturally handled by focusing only on the available data for each pair of features.
- Maximum Likelihood Estimation (MLE):
- MLEs are computed for the means and covariances of the features. For pairs of features, this involves:
- Estimating the mean and variance of individual features using available data.
- Solving an optimization problem for the covariance term using the likelihood function.
- MLEs are computed for the means and covariances of the features. For pairs of features, this involves:
- Efficient Handling of Missing Data:
- The algorithm avoids the computational expense of iterative imputation methods by directly maximizing the likelihood function based on available data, skipping any explicit filling of missing values.
Theoretical grounds
Single class data
In this case, we consider the scenarios where the data comes from one class. This illustrates the fundamental idea of the paper. The cases where the data comes from multiple classes and we want to estimate the pooled covariance matrix can be read in the paper.
Theorem 4.1 for Single-Class Data:
Let a dataset consist of i.i.d. observations following a bivariate normal distribution with mean:

and covariance matrix:

The observations can be arranged as:

Each column represents an observation, and 

The MLEs (Maximum Likelihood Estimates) for the parameters are given as:
Mean (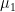
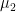
- For feature 1:
whereis the number of non-missing entries in feature 1.
- For feature 2:
whereare the counts of non-missing entries in specific subsets.


Variance (
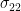
- For feature 1:
- For feature 2:


Covariance (
The covariance 
where:

,
,
.
The maximizer of 

Implications:
This theorem provides a foundation for estimating parameters in datasets with missing values under the assumption of bivariate normality for each feature pair.
- The estimates for means and variances (
) are straightforward sample statistics computed from the available data.
- The covariance (
) requires solving a more complex optimization problem involving the likelihood function. This step ensures that the bivariate normal structure is maintained.
Next, we have this theorem:
Theorem 4.2: Existence of the Covariance Estimator :
In the context of Theorem 4.1, solving for the Maximum Likelihood Estimate (MLE) of the covariance

where:
are defined as sums of squares and cross-products involving the deviations of the observed data from their means (see Theorem 4.1 for details),
are the variances of features 1 and 2, respectively,
is the number of paired observations for features 1 and 2.
Key Results:
Existence of a Real Root:
- The polynomial
always has at least one real root. This guarantees the existence of a solution for
Global Maximum:
- The global maximum of the likelihood function corresponds to one of the real roots of
- This condition ensures that
(the cross-product of deviations) does not take extreme values that could make the solution degenerate.

Implications:
- Uniqueness and Stability:
- While the polynomial may have multiple real roots, the global maximum of the likelihood ensures that the MLE
- The existence of at least one real root provides theoretical assurance that the estimation process for
- While the polynomial may have multiple real roots, the global maximum of the likelihood ensures that the MLE
- Optimization:
- The third-degree polynomial equation
can be solved numerically or analytically to determine
- The third-degree polynomial equation
This theorem confirms the solvability of the covariance estimation problem in the DPER algorithm and ensures that the covariance estimate is theoretically sound and well-behaved.
Algorithm Steps:
- Estimate Means:
- For each feature, compute the mean using only the available (non-missing) values.
- Estimate Variances:
- For each feature, compute the variance using the available values.
- Estimate Covariances:
- For each pair of features, compute the covariance by solving a third-degree polynomial derived from the likelihood function. The solution maximizes the likelihood given the available paired data.
- Iterate Across All Pairs:
- Repeat the above steps for all pairs of features to build the full covariance matrix.
- Generalization to Multiple Classes:
- For multi-class datasets, the algorithm estimates parameters separately for each class (with or without assuming equal covariance matrices).
Benefits:
1. Milder Assumptions:
Bivariate Normality: Unlike many existing methods that assume multivariate normality (a stricter and less flexible condition), DPER only requires bivariate normality for each pair of features. This makes it more applicable to a wider range of datasets, especially those that deviate from multivariate normality.
2. Asymptotic Properties:
Consistency: The Maximum Likelihood Estimators (MLEs) computed by DPER are consistent, meaning they converge to the true parameter values as the sample size increases.
Efficiency: MLEs are asymptotically efficient, achieving the lowest possible variance among unbiased estimators, ensuring that DPER produces reliable estimates.
3. No Iterative Imputation:
DPER directly estimates parameters from the available data without the need for iterative imputation steps. This avoids the potential issues of non-convergence, bias propagation, or overfitting that can arise with iterative imputation methods.
4. Scalability to High-Dimensional Data:
Since DPER performs computations for each pair of features independently, it is scalable to datasets with a high number of features relative to the sample size (a common scenario in modern data settings). This pairwise computation also makes the algorithm inherently parallelizable.
5. Adaptability to High Missing Rates:
DPER handles randomly missing data effectively, and its computational efficiency improves as the proportion of missing data increases (because fewer pairs of data points are processed). This contrasts with many imputation methods that become less reliable or slower with higher missing rates.
6. General Applicability:
Single-Class and Multi-Class Settings: DPER can estimate parameters for single-class data or extend to multi-class problems with or without assuming equal covariance matrices.
Flexibility Across Data Sizes: The algorithm is theoretically sound for both small and large datasets, making it broadly useful in diverse practical scenarios.
Summary:
In essence, DPER transforms the challenge of missing data into manageable pairwise computations, leveraging the bivariate normal assumption to efficiently estimate the underlying distribution of the data.
Discover more from Science Comics
Subscribe to get the latest posts sent to your email.
