Khi đó, chúng ta có thể xem xét về các đặc trưng của thuật toán, bao gồm độ phức tạp tính toán, hiệu suất tối ưu hóa, khả năng tổng quát hóa và các yếu tố ảnh hưởng đến thí nghiệm như chất lượng dữ liệu đầu vào, siêu tham số chưa tối ưu hóa và tiêu chí đánh giá. Cụ thể hơn:
1. Đặc trưng của thuật toán
1.1. Độ phức tạp tính toán
Một thuật toán có độ phức tạp cao hơn sẽ mất nhiều thời gian và tài nguyên hơn để thực thi, làm giảm hiệu suất so với các thuật toán khác.
💡 Ví dụ:
Giả sử bạn đề xuất một thuật toán sắp xếp dựa trên chèn (Insertion Sort) với độ phức tạp 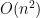
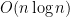
🚀 Cách khắc phục:
- Kiểm tra xem có thể tối ưu thuật toán bằng cách giảm độ phức tạp thời gian không.
- Nếu thuật toán phải chạy trên dữ liệu lớn, hãy xem xét sử dụng phương pháp phân hoạch hoặc tối ưu hóa bộ nhớ.
1.2. Hiệu suất tối ưu hóa
Nếu thuật toán sử dụng tối ưu hóa (như thuật toán di truyền, mạng nơ-ron, hoặc tìm kiếm heuristic), nó có thể hội tụ chậm hơn hoặc mắc kẹt trong cực tiểu cục bộ.
💡 Ví dụ:
Bạn đề xuất một thuật toán tìm kiếm đường đi ngắn nhất sử dụng Hill Climbing. Tuy nhiên, thuật toán này dễ bị mắc kẹt tại các điểm cực tiểu cục bộ và không tìm được lời giải tối ưu toàn cục. Trong khi đó, thuật toán A* có thể đảm bảo tìm được đường đi ngắn nhất nhờ sử dụng heuristic tốt hơn.
🚀 Cách khắc phục:
- Sử dụng phương pháp mô phỏng tôi luyện (Simulated Annealing) hoặc thuật toán di truyền (Genetic Algorithm) để tránh cực tiểu cục bộ.
- Kiểm tra cách thuật toán hội tụ trên tập dữ liệu thử nghiệm và điều chỉnh tham số tối ưu.
1.3. Khả năng tổng quát hóa (Overfitting)
Nếu thuật toán hoạt động tốt trên tập huấn luyện nhưng kém trên tập kiểm tra, có thể nó đã bị overfitting – tức là học quá kỹ các mẫu cụ thể thay vì khái quát hóa cho dữ liệu mới.
💡 Ví dụ:
Bạn xây dựng một mô hình mạng nơ-ron để phân loại hình ảnh mèo và chó.
- Mô hình của bạn đạt độ chính xác 99% trên tập huấn luyện nhưng chỉ 75% trên tập kiểm tra.
- Trong khi đó, một mô hình khác đạt 90% trên cả hai tập sẽ đáng tin cậy hơn.
🚀 Cách khắc phục:
- Sử dụng các phương pháp chống overfitting như Dropout, Regularization (L1, L2), hoặc Data Augmentation.
- Đánh giá mô hình bằng cách sử dụng Cross-validation thay vì chỉ chia tập huấn luyện/kiểm tra một cách cố định.
2. Cách thiết lập thí nghiệm
2.1. Chất lượng dữ liệu đầu vào
Dữ liệu đầu vào có thể ảnh hưởng đáng kể đến hiệu suất của thuật toán. Nếu dữ liệu bị nhiễu hoặc không cân bằng, thuật toán có thể hoạt động kém hơn.
💡 Ví dụ:
Bạn phát triển một mô hình học máy để dự đoán tín dụng ngân hàng, nhưng tập dữ liệu chứa quá nhiều khách hàng có lịch sử tốt *(chiếm 90%) so với khách hàng có rủi ro cao (chỉ 10%).
- Mô hình của bạn có thể chỉ học cách luôn dự đoán khách hàng có lịch sử tốt, mà bỏ qua các tín hiệu quan trọng.
🚀 Cách khắc phục:
- Cân bằng dữ liệu bằng Oversampling hoặc Undersampling.
- Sử dụng các kỹ thuật làm sạch dữ liệu, loại bỏ giá trị ngoại lai.
- Sử dụng bộ dữ liệu khác để so sánh kết quả.
2.2. Thông số thuật toán chưa được tối ưu hóa
Nếu thuật toán chưa được điều chỉnh các siêu tham số (hyperparameters), hiệu suất có thể không đạt tối đa.
💡 Ví dụ:
Một mô hình Random Forest chỉ có ít cây sẽ không khai thác đầy đủ sức mạnh của thuật toán.
🚀 Cách khắc phục:
- Sử dụng Grid Search hoặc thử nghiệm tham số để tìm giá trị tối ưu.
2.3. So sánh không công bằng
Nếu thuật toán không được chạy trong cùng điều kiện với các thuật toán khác, kết quả có thể không chính xác.
💡 Ví dụ:
Bạn thử nghiệm một thuật toán mới trên máy tính có phần cứng yếu hơn, trong khi các thuật toán khác chạy trên máy có GPU mạnh hơn.
🚀 Cách khắc phục:
- Đảm bảo tất cả các thuật toán được thử nghiệm trên cùng tập dữ liệu, cùng phần cứng và cùng điều kiện.
- Chạy thí nghiệm nhiều lần và tính trung bình để đảm bảo độ tin cậy.
3. Phép đánh giá được sử dụng
3.1. Tiêu chí đánh giá không phù hợp
Nếu thuật toán tối ưu một tiêu chí khác với tiêu chí dùng để so sánh, kết luận có thể không chính xác.
💡 Ví dụ:
Bạn tối ưu thuật toán phân loại dựa trên độ chính xác (accuracy), nhưng dữ liệu mất cân bằng (90% mẫu thuộc một lớp).
- Trong khi đó, một thuật toán khác tối ưu theo F1-score sẽ phản ánh hiệu suất mô hình tốt hơn.
🚀 Cách khắc phục:
- Sử dụng các chỉ số phù hợp như Precision, Recall, AUC-ROC, F1-score, thay vì chỉ nhìn vào Accuracy.
3.2. Độ tin cậy của kết quả
Nếu kết quả bị ảnh hưởng bởi nhiễu hoặc số lần chạy quá ít, có thể kết luận chưa chính xác.
💡 Ví dụ:
Bạn đánh giá thuật toán với chỉ 1 lần chạy và thu được kết quả thấp.
- Nhưng thực tế, nếu chạy 10 lần, kết quả có thể ổn định hơn.
🚀 Cách khắc phục:
- Chạy thuật toán nhiều lần và tính trung bình để giảm sai số do nhiễu.
- Dùng Cross-validation thay vì chia tập dữ liệu cố định.
Tổng kết
| Nguyên nhân | Ví dụ cụ thể | Cách khắc phục |
|---|---|---|
| Độ phức tạp cao | Insertion Sort vs QuickSort | Chọn thuật toán tối ưu hơn |
| Mắc kẹt cực tiểu | Hill Climbing vs A** | Sử dụng heuristic tốt hơn |
| Overfitting | Mô hình quá khớp dữ liệu huấn luyện | Regularization, Data Augmentation |
| Dữ liệu nhiễu | Dữ liệu không cân bằng | Resampling, làm sạch dữ liệu |
| Siêu tham số chưa tối ưu | Random Forest với ít cây | Grid Search, thử nghiệm tham số |
| So sánh không công bằng | Chạy trên phần cứng khác nhau | Giữ điều kiện thí nghiệm đồng nhất |
| Tiêu chí đánh giá sai | Accuracy thay vì F1-score | Chọn metric phù hợp |
| Số lần thí nghiệm ít | Chạy 1 lần chưa đủ | Lặp lại nhiều lần, Cross-validation |
📌 Bạn có thể kiểm tra lại thuật toán theo các tiêu chí trên để tìm cách cải thiện.
Discover more from Science Comics
Subscribe to get the latest posts sent to your email.