Proof:
Let’s define a general convex quadratic function:

where 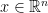



The gradient of this function is:

Lipschitz Continuity
A function 



where 
We want to show that for our quadratic function, 

Let’s compute the difference of the gradients at two points 


Now, take the norm:
We need to find a bound for 

From linear algebra, we know that for any vector 


For a symmetric matrix, the operator norm is equal to its largest eigenvalue (in absolute value). Since
Therefore:

Substituting back into our Lipschitz continuity equation:


This shows that the gradient of the quadratic function 

Since the MSE loss function in linear regression is a convex quadratic function, this result applies directly. The Hessian of the MSE loss is 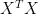
Discover more from Science Comics
Subscribe to get the latest posts sent to your email.