An Introduction to Flow Matching
Flow Matching is a powerful and relatively new framework for training generative models. It has quickly become a state-of-the-art method, rivaling and in many cases surpassing established techniques like diffusion models. In essence, Flow Matching provides a simpler, more efficient, and often more stable way to teach a machine how to generate new data (like images, audio, or video) that looks like a dataset it has been trained on.
The Core Idea: From Noise to Data
Imagine you have a pile of random sand (this is your “noise” distribution) and you want to arrange it into a beautiful, intricate sculpture (your “data” distribution). How would you guide each grain of sand from its random starting position to its precise final location in the sculpture?
Flow Matching solves this by learning a velocity field. This field is governed by an Ordinary Differential Equation (ODE), which provides a continuous map from the noise distribution to the data distribution. It’s like a set of instructions that tells every single grain of sand exactly which direction to move and how fast to go at any point in time. By following these instructions, the chaotic pile of sand smoothly and continuously “flows” into the desired sculpture.
In machine learning terms:
- The “sand” is a vector in a high-dimensional space.
- The “pile of random sand” is a sample
x₀from a simple probability distributionp₀(e.g., a standard Gaussian or “normal” distribution). - The “sculpture” is a sample
x₁from the complex data distributionp₁you want to learn (e.g., the distribution of all possible realistic cat images). - The “instructions” are a neural network
v_θtrained to predict the velocity vector for any pointxat any timet.
How It Really Works: The Technical Details
The primary goal is to learn a continuous transformation, or “flow,” that can morph a simple base distribution (e.g., random noise) into a complex, high-dimensional data distribution (e.g., realistic images).
This transformation is modeled as a continuous path over a virtual time 
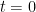
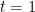
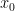
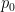

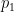
This entire process is governed by an Ordinary Differential Equation (ODE), which is defined by a time-varying vector field, denoted as 



The central challenge in training such a model is that the true vector field 
Conditional Flow Matching (CFM): The Solution
Conditional Flow Matching (CFM) provides an elegant solution to this problem. Instead of trying to learn the single, impossibly complex vector field for the entire distribution, CFM simplifies the problem by learning many simple flows and averaging them.
The key insight is to define a conditional probability path 



For instance, we can define a simple linear path between the noise and the data point:

The vector field required to keep a point on this straight-line trajectory is simply the difference vector:

The “matching” in Flow Matching comes from training a neural network, 
The CFM loss function is formulated as:
![\mathcal{L}{CFM}(\theta) = \mathbb{E}{t, x_1, x_0}\left[ \left| v_{\theta}(x_t, t) - u_t(x|x_1) \right|^2 \right]](https://s0.wp.com/latex.php?latex=%5Cmathcal%7BL%7D%7BCFM%7D%28%5Ctheta%29+%3D+%5Cmathbb%7BE%7D%7Bt%2C+x_1%2C+x_0%7D%5Cleft%5B+%5Cleft%7C+v_%7B%5Ctheta%7D%28x_t%2C+t%29+-+u_t%28x%7Cx_1%29+%5Cright%7C%5E2+%5Cright%5D&bg=ffffff&fg=000&s=0&c=20201002)
where the expectation 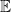
![t \in [0, 1]](https://s0.wp.com/latex.php?latex=t+%5Cin+%5B0%2C+1%5D&bg=ffffff&fg=000&s=0&c=20201002)
![\mathcal{L}{CFM}(\theta) = \mathbb{E}{t, x_1, x_0}\left[ \left| v_{\theta}((1-t)x_0 + t x_1, t) - (x_1 - x_0) \right|^2 \right]](https://s0.wp.com/latex.php?latex=%5Cmathcal%7BL%7D%7BCFM%7D%28%5Ctheta%29+%3D+%5Cmathbb%7BE%7D%7Bt%2C+x_1%2C+x_0%7D%5Cleft%5B+%5Cleft%7C+v_%7B%5Ctheta%7D%28%281-t%29x_0+%2B+t+x_1%2C+t%29+-+%28x_1+-+x_0%29+%5Cright%7C%5E2+%5Cright%5D&bg=ffffff&fg=000&s=0&c=20201002)
By minimizing this objective, the neural network 
Flow Matching vs. Diffusion Models
- Pathways: Diffusion models learn to reverse a specific, fixed stochastic process of adding noise. Flow Matching can use a wider variety of paths, including deterministic straight lines, which makes training more direct and stable.
- Training Objective: Diffusion models use a score-matching objective to predict the noise added at each step. Flow Matching uses a simpler and often more stable L2 regression loss to predict the flow vector directly.
- Optimal Transport Paths: Flow Matching can leverage paths from Optimal Transport (OT) theory. These paths represent the most efficient way to morph one distribution into another. Using OT paths can lead to even faster training, quicker sampling, and better model generalization compared to standard diffusion or straight-line paths.
- Sampling: Because Flow Matching learns a deterministic flow via an ODE, sampling can be significantly faster, requiring fewer function evaluations (NFE) from the model to generate a high-quality sample.
Key Advantages Summarized
- Efficiency: Simulation-free training is fast. Inference is also fast due to the efficiency of modern ODE solvers and the high quality of the learned vector fields.
- Simplicity & Flexibility: The core concept is more straightforward, and the regression-based loss is easier to implement and stabilize than score-matching losses.
- Stability: The training process is demonstrably more stable, leading to reliable convergence.
- High Performance: Flow Matching models have achieved state-of-the-art results on many benchmarks for image, audio, and video generation.
Conditional Flow Matching: A Simplified Approach to Generative Modeling
Conditional Flow Matching (CFM) is a powerful and efficient technique for training generative models, particularly a class of models known as continuous normalizing flows (CNFs). At its core, CFM simplifies the complex task of learning a high-dimensional data distribution by breaking it down into a multitude of simpler, one-dimensional problems. This is achieved by learning the “flow” or transformation from a simple noise distribution (like a Gaussian) to each individual data point, and then averaging these individual flows to approximate the overall data distribution.
This “conditional” approach, where the model is conditioned on a specific data sample, makes the training process significantly more stable and computationally tractable compared to traditional methods. It avoids the need for costly simulations during training, leading to faster convergence and more efficient model development.
The Intuition: From a Complex River to Simple Streams
Imagine trying to model the complex flow of a wide river. Unconditional flow matching would attempt to capture the entire river’s dynamics at once – a formidable task. Conditional Flow Matching, in contrast, is like studying the flow of individual streams that feed into the river. By understanding the behavior of these simpler streams and how they combine, we can build a comprehensive picture of the entire river.
In the context of generative modeling, the “river” is the intricate distribution of your data (e.g., all possible images of cats), and the “streams” are the individual paths from random noise to each specific cat image in your training dataset. CFM trains a neural network to learn these individual paths, or “conditional vector fields.”
Mathematical Underpinnings: Regressing on Vector Fields
Mathematically, a continuous normalizing flow is described by an ordinary differential equation (ODE) that defines a continuous transformation from a simple base distribution p0 to a complex target data distribution p1. The goal is to learn the time-varying vector field vt(x) that governs this transformation.
The challenge is that the true vector field of the marginal flow is often intractable. Conditional Flow Matching cleverly sidesteps this by defining a conditional probability path pt(x∣x1) from a noise distribution to a single data point x1. This conditional path has a much simpler, well-defined vector field ut(x∣x1).
The CFM loss is then a straightforward regression objective: it trains a neural network vθ(x,t) to predict these conditional vector fields for different data points and time steps. The loss function is typically the mean squared error between the predicted and the true conditional vector fields. By minimizing this loss, the neural network learns to approximate the individual “streams,” and through the aggregation of these learned conditional flows, the model can effectively sample from the entire data distribution.
Key Differences: Conditional vs. Unconditional Flow Matching
| Feature | Conditional Flow Matching (CFM) | Unconditional Flow Matching |
| Core Idea | Learns the flow conditioned on individual data points. | Learns the entire flow from noise to the data distribution at once. |
| Complexity | Breaks a complex problem into many simpler ones. | Tackles the high-dimensional learning problem directly. |
| Training | Typically more stable and computationally efficient. | Can be unstable and computationally expensive. |
| Tractability | The conditional vector fields are often easy to define and compute. | The marginal vector field is usually intractable. |
Relationship with Diffusion Models
Conditional Flow Matching shares a close relationship with another popular class of generative models: diffusion models. In fact, under certain conditions, particularly when using a Gaussian probability path, CFM can be shown to be equivalent to diffusion models.
Both approaches involve a “forward process” that gradually adds noise to data and a “reverse process” that learns to denoise and generate data. However, CFM offers a more generalized framework that is not restricted to Gaussian noise, providing greater flexibility in model design. A key advantage of CFM is its potential for faster sampling, as the learned flows can be “straighter” than the paths learned by traditional diffusion models, requiring fewer steps to generate a high-quality sample.
Applications of Conditional Flow Matching
The efficiency and flexibility of CFM have led to its successful application in various domains, including:
- Image and Video Generation: Creating realistic and diverse images and video sequences.
- Audio and Music Generation: Synthesizing novel audio waveforms and musical pieces.10
- Time-Series Modeling: Forecasting and generating complex time-series data.
- Robotics: Learning smooth and natural trajectories for robot movements.
- Computational Biology: Modeling single-cell dynamics and other biological processes.
In conclusion, Conditional Flow Matching represents a significant advancement in generative modeling, offering a more intuitive, efficient, and versatile framework for learning complex data distributions. Its ability to simplify the learning problem through conditioning has paved the way for more powerful and accessible generative AI.
Read more:
https://neurips.cc/virtual/2024/tutorial/99531
Improving and generalizing flow-based generative models with minibatch optimal transport
Example of conditional-flow-matching on MNIST (github) .